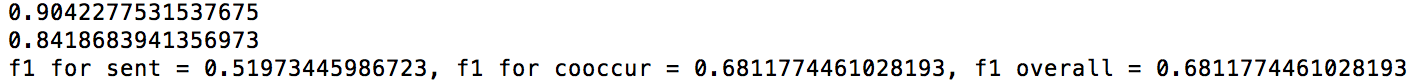Comparison and Generation of YouTube Comments
By: Will Burford, Vincent Lin, Haoyu Sheng, Tongyu Zhou
Abstract:
Consider a user or a company attempting to generate the most social impact through YouTube. What should they do to get the most likes? What are the determining factors that contribute to the popularity of the most-liked comments? The goal of our project is to develop a binary classifier that will determine which of two given Youtube comments will receive the most likes through features such as cooccurrences and sentiment polarity scores, and ultimately generate the YouTube comment that will get the most likes from a given video’s metadata through methods such as Recurrent Neural Network and Markov Chain Bigram Model. The sentiment analysis classifier and co-occurrence classifier result in f1 scores of 0.51 and 0.68, and we are able to generate sensical phrases based on the category.
1. Introduction:
We are seeking to create a system which will be able to produce the top comment on a trending YouTube video. This has two potential applications for industry. It would allow advertisers to insert advertisements into the comments of a YouTube video free of charge. This would also be a preferred location to put an ad because it would not be censored by an ad-blocker and is more likely to be read and interacted with by users than a banner. Additionally, it would allow YouTube to better understand which comments should be surfaced to users before a critical mass of comments is aggregated. This would allow a person viewing the video close to the time of release to still see the best comment available at that time.
2. Survey of Existing Work(s):
1. Retweeting Behavior Prediction: based on analysis of four features (user status, content, temporal, and social tie formation). Of these features, content and temporal are most relevant to us. Temporal analysis places emphasis on the time frame the tweet was created. Content analysis revealed that the inclusion of certain sentiment words that convey emotion (positive, neutral, negative) and a strong correlation between the user’s profile and the topic of interest in the tweet (categorized using OpenCalais) garnered higher numbers of retweets.
2. Usefulness of Youtube Comments: analyzing and predicting youtube comments and comment ratings”.This paper analyzes the dependencies between Youtube comments, views, comment ratings and topic categories. In addition, they studied the influence of sentiment expressed in comments on the ratings for these comments using the SentiWordNet thesaurus, a lexical WordNet-based resource. Finally, to predict community acceptance for comments not yet rated, they built different classifiers for the estimation of ratings for these comments. [2]
3. Writing Quality Predictor: Annie Louis and Ani Nenkova used a classification model that built different feature vectors of models of writing.[4]
Because of the nature of YouTube comments, which are usually filled with vulgar languages and nonsensical grammars, there are very few established papers and these research only serve inspirational purposes. As a result, we decided to go our own way[5].
Note: There are many other works that we’ve surveyed and we embedded the works that are more relevant in our specific section of classification or generation.
3. Formulation:
For the popularity classifier, we originally decided to build a Naive Bayes classifier to predict the number of likes each comment is likely to receive. However, due to the unbalanced nature of the dataset that most comments have zero likes, the classifier is very likely to overfit while only outputting 0. In order to avoid this conflict, we decided formulate the more likely to be liked comparator as a binary classification problem where our input consists of comment pairs.
For the comment generator, we represent it as an ngram language model and a deep learning problem. For the ngram language model, we apply smoothing and markov chain. For the deep learning model, we constructed a recurrent neural network, which takes in all the unique characters in the comment corpus, outputs a vector of the same length comprised of 0s’ and 1s’ to indicate which character is generated, and unrolls sequentially to output the word sequence.
The implementation details will be further discussed in the Methodology section.
4. Methodology
Classification: We used an ensemble approach to classification. The two classifiers we used were co-occurrence and sentiment analysis. The details of each are covered below. We used a weighted voting process to combine the outputs of the classifiers, with co-occurrence weighted more highly because it has a significantly better f1-score. The data supplied to both classifiers is only the comment data on the specific video that we are generating for.
Co-occurrence:
Baseline: The initial approach to the co-occurrence model did not use any machine learning libraries. It took a single input comment, split the it into tokens, and went through all of the comments in the dataset to find the most similar existing comments based on co-occurrence similarity. It then averaged the likes from the most similar comments and assigned that number of likes to the input comment. This method did not perform very well because the data on likes was very sparse and it was common for a comment to get 0 likes as an output, which did not help when comparing two comments.
Version 1: The next iteration of the co-occurrence model implemented a Naive Bayes classifier using a bag of words feature vector. The input was a single comment with its number of likes, and the classifier attempted to assign a number of likes to the new comment based on the data it had compiled by training on the training set. This model did not work because the classifier overfit to our dataset, which was filled with mostly 0 likes. For this reason, almost every input comment was 0 likes, which also was not useful for comparison between two comments, as we needed for deciding which generated comment would perform the best.
Version 2: The final version of the co-occurrence classifier continues to use Naive Bayes on a bag of words feature vector. However, we changed our classification question to choose the more liked of two comments rather than assign a single comment a number of likes. Our feature vector is now two concatenated bags of words, the first section being the first comment and the second section being the second comment. The classifier was trained on a training set of the format (comment1, comment2, winner), where winner was either 0 if the first comment received more likes or 1 if the second comment did. We ran through every possible combination of comments in the training set during our training session, then we tested on every combination of comments in the testing set to compute the f1-score. When running to decide which which generated comment will receive more likes, we use pass through every combination of comments in the dataset for the given videos for training.
Sentiment analysis:
Baseline: Word-based + Naive Bayes + entire corpus
The simplest version was based on the assumption that more positive comments would accordingly garner the most likes, so we performed word-based sentiment analysis by using a NLTK lexicon that already contains hundreds of thousands of sentiment-based words tagged with a polarity-based approach (assigned with either “pos”, “neg”, or “neu”). Using the top ten comments of each video, we first removed all stop words and then trained a Naive Bayes Classifier using the presence of positive words as a feature vector. Unfortunately, this did perform so well as we failed to take into account the actual nature of realistic youtube comments that generally was not so wholesome.
Version 1: Sentence-based + Naive Bayes + per category
Because word-based sentiment analysis took too long, required additional POS-tagging, and did not fully capture the general sentiment of the comment, we swapped to sentence-based sentiment analysis with VADER. This time, we do not remove stop words nor emoji as both are factored into the lexicon, which generates a compound score for each sentence. Instead of running the Naive Bayes classifier over the entire training corpus, we took the average sentiment scores per category, assuming that each category can be associated with an average comment sentiment score (for example, Gaming would have a much lower one than Lifestyle). This was also not as effective, however, as video comments were also heavily dependent on the particular fanbase that a Youtube creator gathered.
Version 2: Numerical difference sentence based + Naive Bayes
Instead of taking the sentiment scores for individual sentences, we decided to store the differences of these scores instead, matched with a value of 0 (first comment has more likes) or 1 (second comment has more likes) as the feature vector for the Naive Bayes classifier, as this would further reduce runtime because in training, we already performed the comparisons. The scope of the comments was reduced to multiple videos chosen randomly from the given category to correct for the disparities in category size.
Follow up:
A further extension is to build on the work of Amy Madden, Ian Ruthven, and David McMenemy, who constructed a classification scheme for content analysis of Youtube comments, splitting each into one of 10 categories, under which there were many more subcategories.[6] Following their same strategy of deviant case analysis, we can associate sentiments with each category, which may be more informative than taking video categories since we are really in truth only interested in the content of the comments themselves. However, considering a large proportion of our corpus consisted of comments with no likes at all, with some whole videos falling into this category, and we only trained on comments with higher number of likes, we would probably not have enough training data to perform a meaningful analysis. Due to the limitations of the dataset, this model would theoretically work best if the likes per comment category followed some form of normal distribution.
Generation and Language Model:
Data Preprocessing:
For our data processing, you are encouraged to enter in the tags, the title, and the category of the youtube video. From these informations, we create data file that contains all the comments from videos that have the same category and any keywords (no stop words) from the tags and the title. We then use these comments to generate our language model, which will produce the final comments.
Baseline: Ngram model with no smoothing
The simplest version of this language model is an Ngram model. After testing different number of grams, we decided to do trigrams for hopefully the best coherence.
Version 1: Ngram model with smoothing with Katz backoff.
We want to test the smoothing effects on the comprehensibility and the coherence of the text. It allows for more original generations, but it seems highly unlikely that that this will yield a more coherent text than that of our N-Gram Model. We predict that it will yield a worse coherence than the baseline version.
Version 2: Generalized smoothing method based on likes.
Since we want to generate comments with higher chances of likes, we want to give more weights to the comments with more likes. Our initial weight to give to the comments will be for every extra like, we will give one extra word for likes. So we will replicate each comments once per like so this will be smoothed for all language models. We will be trying out different weighting, such as multiples of 2, 3, 4 to find out the best weight.
Version 3: Markov Chain Bigram model
We used a Markov Chain to store the probabilities of transitioning from a present state to the next state using a bigram model primarily because working with trigrams and above would take too much time. We assume that all words that appear after a preceding word have the same probability, so we stored all the next states, including repetition, as values in a dictionary and used randomization to choose the next probable one. As the corpus increases, the model will naturally become more weighted accordingly to frequency. We believe this would be a better alternative to the previous language models as dynamic programming allows for more efficient space and time allocation. This improved the runtime by several minutes.
Version 4: Markov Chain Model with a grammar rating model (FAILED took too long to run).
We attempt to use the Stanford coreNLP parser to parse the comments into grammar trees. Then we take these grammar trees and count up same structures of the grammar tree. Then, we generate a probability for each grammatical rule. From these probability, we will rate the comments generated by our Ngram model and take the top 64 comments based on the probability of these comments. We took inspiration from papers attempting to combine the Ngram model and PCFG model. See.[7]
The primary reason why we didn’t implement a PCFG model is because several assumptions of PCFG model cannot be assumed in the case of Youtube comments. First, most of the youtube comments are not in grammatical form. Second, the youtube comments will often be tokenized into words that are not correctly spelled. In other words, there will quite a few trolling comments. Both of these features of our dataset does not suit well for PCFG model since there will simply be too many forms of grammar in these Youtube comments. From the literatures we’ve exam, the general consensus is that PCFG is worse than the NGram model for English
Version 5: Markov Chain model with Named Entity Tagger.
We noticed that that some of the comments generated contained Named Entities that are relevant to the title or the tags of the video. So we’ve decided to replace the Named Entity generated in each comment generated with the Named Entities in certain comments. This is done through a probability generation weighting the Named Entity.
Deep Learning Version: Character-based RNN Model.
We ran two versions of the Recurrent Neural Net Model: one basic version and another with LSTM. Both of these versions were implemented by Andrej Karpathy, which is included in the source code.[8]
Vanilla RNN Version:[9]
This model will take in the corpus and find the set of unique characters being used and use that to generate a binary feature features with one being the character that appears and zero being the character that does not appear. This cuts down drastically on the size of the matrices. It is unrealistic for us, who has very little computing power, to do word-based generation since there are at least 100,000 unique words in these youtube comments, which means a feature vector of length of at least 100,000.
In the Vanilla Version of this project, the neural network comprise of 2 hidden layers. With each layer of matrices and its weights being randomized initially and altered through a back-propagation function based on an entropy model. The back-propagation function alters the weights by calculating the derivative of weight of one node to the previous node and then adjust the values of the matrices to better match the contour of the data points. By altering the value of the matrices of each node, it will alter the weights of each features, which will change the value of the final value of the end node. For more see footnotes.[10]
LSTM Version:
The LSTM Version added an Long Short Term Memory gate to it, which allows the extraction of long-term features of these vectors to be remembered better. Each node in the neural vectors, which contains different weights will be regulated by the LSTM, which will determine how much weight to give to each vectors. For example, the gender of the speaker will be difficult for the language model to capture in the its generation. However, since LSTM regulates the memory of the vectors. It’ll do a better job of capturing these long term dependencies.[11]
Evaluation Metric of Language Model:
Since we are only generating 64 comments per language model. We will be using an extrinsic evaluation metric and rating it by hand by giving it a score of 0-5 for coherence for each file by our 4 group members! We chose not to use the perplexity to rate the language model since our data is extremely sparse and it is extremely clear which language model is superior.
5. Experiment and Analysis:
Experiment Setup:
Dataset: Our dataset was obtained from Kaggle and contains information scraped from YouTube about trending videos at the time of collection. The dataset contains metadata for about 8,000 videos as well as around 700,000 comments with their corresponding like-counts. We found that this data was incredibly sparse as vast majority of comments received no likes.
Preprocessing: Not much preprocessing was required for this dataset. Apart from dealing with non-ASCII characters, the data was already formatted in a made it easy to work with.
Train/test sets: We split our dataset into two parts: 70% for training and 30% for testing. We used these to calculate the f1-score for our classifier, but when we run our classifier on our generated comments we use the whole dataset as training data.
For the Comment generation portion of the corpus, we were correct in most of our predictions about the versions that we’ve ran. The overall best model is the Markov Chain Bigram Model without Smoothing and with NER replacement.
Classification:
Scores:
The above metrics is for the non-pairwise version of the sentiment analysis and the co-occurrence analysis. The top two values, 0.88 and 0.60, are the accuracies of our training set. Our f1 values for the classifiers are included as well. As we can see, the f1 for co-occurrence is 0 since comments with 0 like occupies around 60% of the dataset, which results in the overfitting classification of 0.
The top two values, 0.90 and 0.84, are the accuracies of our training set. Our f1 values for the classifiers are included as well. For the overall f1 score, we weighted the language model for co-occurrence heavier since it produced the comparatively higher f1 score.
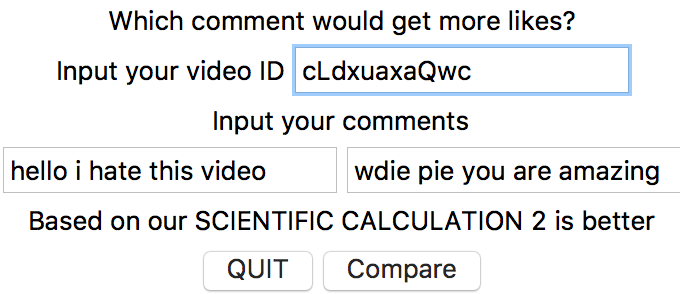
Above is a simple illustration of the current performance of the classifier. It seems to capture the important phrases such as “pewdie pie” and how that correlates to the relative popularity of a comment instead of simply returning 0.
Specific Examples:
Comments | Sentiment | Co-occurrence | Ensemble | Correct |
I forgive you Vs. I don’t have respect for you | 0 | 0 | 0 | 1 |
Tf did he say?? Vs. to what | 1 | 1 | 1 | 0 |
Like if agree Vs. Well I accept your apology Mr PewDiePie. It just slipped out. You are still a good YouTuber | 1 | 1 | 1 | 1 |
Here, we see in all cases that the sentiment classifier is picking the generally more positive sentiment comment. The fact that the sentiment classifier is not always correct shows us that our assumption that a more positive comment receives more likes does not hold 100% of the time. The co-occurrence model incorrectly classified the first two comment pairs. This is likely because the comment pairs that we had used for training generally had a comment more like “I forgive you” or “to what” winning the dual over a comment such as “I don’t have respect for you” or “Tf did he say??” respectively.
Generation:
Scores: Rating of Language Model:
Baseline: | Markov Bigram: | Markov Trigram: | Deep Learning: |
2.5 | 4.5 | 4.25 | 3.5 |
Ngram Model:
When we first viewed the comments generated in the Ngram model, we were in disbelief at how incoherent and illogical most of these comments were. As it turns out, we tested our language model on the shakespeare corpus and it yielded substantially better results. So we digged into our data set and read many Youtube Comments and we discovered that data set contains the following problems:[12]
Since this dataset is scrapped at 12:00am everyday and for the top 200 trending videos, there are often times numerous comments that are not liked. The majority of the comments are of 0 likes and the ones that are liked are usually 1 or 2 likes. This resulted in our Well-Like Smoothing feature producing results that are not significant in its generation.
This includes a repetition of certain derogatory words over and over again. Our record is one person repeated a racial slur 325 times in one comment, which lead us to only take the first 20 words of every comments in our corpus generation. Most of the comments are in different forms and there are many different sentences with little recurrence such the bigram probability of each sentences are quite evenly distributed on the lower end. This signals that our dataset is actually not largely enough to generate the model properly.
Most comments on youtube contains incorrect spellings and an abundance of punctuation marks, such as ……!!!!!!. Some of the comments also skip several lines and contain absurd drawings based on unique characters and emojis. Furthermore, some of the comments contains incorrect grammar. These features of the youtube comments make the comments to be extremely random. This factored into why we decided to remove version 4.
Smoothing with Katz Backoff Feature:
As predicted, smoothing decreases the coherence of the sentence generated. This did increase the diversity of words by making the comments generated more incomprehensible (which we did not think it was initially possible).
NER replacement feature:
Our NER replacement feature Tagger was extremely beneficial. However, for some NER, because the grammar was messed up, the POS-tagging layer of NER tagger could not tag it correctly. Furthermore, some of the named entities and comments are in the transcript of the video, which we could not obtain. Thus, some of NER are incorrectly placed in the context of the video. For example, in the appendix, the NER tagger replaced England incorrectly Hart in line 9.
Version 4 Failure: Our original idea for the grammar rating model is to use NLTK’s Viterbi parser to generate probabilities based on all possible grammar trees of a particular sentence. From these probabilities, we would return sentences that generated the top probabilities. However, in order to create a grammar structure that was compatible with the format that NLTK accepts, we needed to parse from a treebank file that would take too long to run through all the comments of the videos.
Deep Learning Model:
For the Deep Learning Model, we ran through 20110 iterations of the vanilla model of RNN, which took around 5 hours on CPU and 63000 iterations of the LSTM version of RNN, which took around 19 hours on the CPU. The vanilla version plateaued at a training loss of 44% and the LSTM version plateaued at a training loss of 32%. Screenshots of the result are included in the appendix. When we look at the results for both deep learning model, once again the misspellings and punctuations repetition really decreased the fluency and coherence of the language model. However, if we spell-checked and remove all punctuations, this language model would perfectly suffice. In the future, we would want to run this model on a computer with a dedicated GPU and test out different hyperparameters and backpropagation functions in order to get a better result. Note, we were unable to run the NER changer and Grammar rating model since most of the words are misspelled and often makes no sense.
Conclusion:
We were surprised at the progress we made in terms of an f1-score for predicting comment likes with solely using the assumption that the more positive comment will receive more likes. When we combined this with the bag of words model, we saw that our f1-score increased more. One of the major weakness of the project was the dataset we were using. The likes on the comments were very sparse, with whole comment sections only having a few likes at times. If we were to do this again, we would make sure to scrape our own data from YouTube so that we could ensure a higher density of like data.
We were unsurprised that markov chain bigram model got the best score as the nature of our sparse data mentioned. An extension that we would work on in the future in to successfully create and test Version 4 of our data. Furthermore, we would like to explore the RNN language model by testing out different hyperparameters and backpropagation functions in order to get a better result.
In future work, we would like to extend this work to predicting similar comment-like relationships. This could be on other platforms such as Facebook or Instagram. On a platform such as Facebook, the program could even be extended so that it would be able to predict the number of likes on an original post.
Appendix:
Contributions:
Haoyu worked on both classifiers, data handling, and is very proud of the GUI that he made.
Tongyu worked on the sentiment classifier and the language model versions of the generation.
Vincent worked on all versions of language model and deep learning generation.
Will worked on the co-occurrence classifier, dataset handling / validation, and combining the generation with the classifiers into a unified system.
Top 10 Generated Comments for Language Model:
Bigram Markov Chain Model:
Bigram Markov Chain with NER: The title of the video is “Florida Man Stole Kevin Hart's Attention at the NYC Marathon.”
Deep Learning LSTM Version:
[7] https://pdfs.semanticscholar.org/adbb/58b693ba0211aac392fb2c49a71c8eecfa7a.pdf and http://www.aclweb.org/anthology/P94-1011
[8] Karpthy’s talk on RNN and his implementations of Character-based RNN Model with LSTM https://skillsmatter.com/skillscasts/6611-visualizing-and-understanding-recurrent-networks
[9] Basic explanations of RNN http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[11] For more informations, see http://colah.github.io/posts/2015-08-Understanding-LSTMs/ which explains LSTM very well.
[12] For research and entertainment purposes, this article enlightened us on the methodology of Youtube comments being upvoted, the lack of oversight and moderation and the encouragement of trolling by various communities. https://www.newstatesman.com/science-tech/internet/2016/10/why-are-youtube-comments-worst-internet